
Mistakes I Made Approaching Eval-Driven Development
Learning to Classify Failure Modes Before Automating Them

Reading Chip Huyen’s AI Engineering has been harder than I expected. Most of it assumes you’re already an ML engineer.
I’m a software engineer, and I was trying to force theoretical evaluation thinking onto what can be evaluated deterministically.
I also realize that I need to read this book. Instead of going chapter-by-chapter like Designing Data-Intensive Applications (Kleppmann), I treated each chapter like a map: skim for the ideas, then go learn the fundamentals elsewhere on the internet.
The best way for me to learn is still building. So I started a quarterly report summarizer, and I tried to implement the evaluation-driven development approach from chapter 4.
My first attempt was to follow the book suggests: define eval criteria, build an AI judge, automate scoring.
It takes alot of time to create the AI Judge. The prompt became its own mini product. I need to think about tolerance rule, output format, and ended up focusing too much on evaluating the evaluator.
That’s when I started reading more product-focused discussions about evlaution. I stumble upon a post by Hamel Husain (link) and finally made it click.
Here are some of the mistakes that I noticed right away:
Mistake #1: Jumping Straight to an AI Judge
I went straight to an AI Judge. Since that is what was emphasized in the book, to automate the evaluation of your AI model.
If you can remove or simplify something before automating it, do that first.
An AI judge can be slow, expensive, and non-deterministic. If you jump straight into it, it increases your development time - and sometimes it’s just overkill.
I was using it to evaluate numerical accuracy. I was spending time tuning tolerance for things like $84.54B vs $84.544B and resolving the discrepancy between the income loss of 90.19 million and the -90,190,000 shown in the source file.
Soon, I realized that the problem can be further deduced into a functional correctness problem by categorizing them as deterministic failures.
Two Types of Failure Mode
This was the biggest lightbulb moment for me. Husain classified two types of failures: deterministic failures and subjective failures, and I was mixing them.
Hamel Husain describes two types of failure that you can evaluate AI applications:
Deterministic failure: closed-ended, objectively checkable (functional correctness)
Subjective failure: open-ended, requires judgement (often needs human labels)
In AI Engineering, deterministic failure is identified as functional correctness. It means that the output is objective and it is closed-ended. For example, if I want to evaluate the chat, “What is the revenue of AAPL last quarter 2025?” There is 1 objective output.
A subjective failure is more nuanced. The answers are usually open-ended, and they require product judgment on a case-by-case basis. For instance, if I want to ask if the Apple earnings calls in the last quarter contain a positive or negative sentiment, the answer will be nuanced and based on how each person perceived its response. This usually requires human annotation judgment to teach AI to evaluate its output.
For my quarterly earnings summary, numerical accuracy is deterministic. I am not trying to ask for any interpretation. I just want to ensure that the number in the result matches the one in the source.
Mistake #2: My Metrics Were Too Generic
I used “Hallucination” and “Numerical Accuracy”.
Hallucination is too generic. It can mean a wrong unit, a completely invented number, or the wrong sign. In this case, it was meant to be a completely invented number that doens’t exist in the source document.
Worse, my two metrics were basically the same. If number accuracy failed, I also counted it as hallucination. So every mismatch turned into a double-failure—without telling me what to fix.
Mistake #3: Not Enough Data for AI Judge
AI Judge works if you have an enough amount of data to train and evaluate with the AI Judge. Not only that, AI judges are best when you are evaluating more subjective failure types of data.
Hamel Husain outlines a process that is great for developing a good AI Judge:
Manually annotate your data (this can be coming from a real user or coming from synthetic data). These steps are important because they will create a reference to teach the AI judge and to evaluate what is right and wrong.
Use 20% of the data for the training set. This is the data that you provide to the AI judge in the prompt so that the model can discern the right judgment.
Use 40% of the data as a dev set. This test set is to test the AI Judge to ensure that the evaluation is correct and that it follows the annotation that you mentioned in your dataset.
Use the last 40% for the real test set. This is when the AI judge will evaluate the last 40% of your data after going through multiple training sets and prompt refinement.
Then, you track the TPR and TNR metrics to indicate how confident you are with your AI judge before applying it as an evaluation.
I didn’t do any of that. I assumed the judge was correct initially, and it turns out that the judge was too sensitive and brittle.
Update on the Quarterly Report Summarizer
After I classified the failure mode, I changed the way I evaluate the quarterly report summarizer.
Since I only focus on numerical analysis, I dropped the hallucination metric and opted for a code-based evaluation for evaluating this criterion in my quarterly earnings summarizer.
The high-level idea was to treat them like a unit test - by:
Extracting the numerical value from the summary
Assert them against the source canonical table
Generate a report showing that the numbers that were summarized are numerically accurate.
However, since it is a summary, which is open-ended, evaluating numerical accuracy with code-based methods can be quite tricky. The summarizer can provide various forms of numbers that can be different from the source table. It can also provide different rounding rules that may not be exactly the same as the source file. Lastly, I don’t want to use an AI to judge the result. Thus, I need to parse the unstructured data into a structured format in order to compare it against the source value.
Here is the solution that I came up with to ensure that I can extract all values within the unstructured data and assert them to the source data in a single function.
Make the Summary Machine-Readable
In order to easily parse all the numbers within the summary into a structured format, I need to make the output summary parseable.
For example, the current output of the summary looks like this:
- Cloudflare, Inc. reported a net income loss of $90.19 million for Q3 of 2025, indicating a challenging financial period. (concept=us-gaap:NetIncomeLoss, unit=USD, period_end=2025-09-30, accession=0001477333-25-000141)
- The company’s diluted earnings per share (EPS) showed a loss of $0.26, reflecting ongoing struggles in profitability. (concept=us-gaap:EarningsPerShareDiluted, unit=USD/shares, period_end=2025-09-30, accession=0001477333-25-000141)
- Cash and cash equivalents stood at $1.05 billion, providing a solid liquidity foundation despite the current losses. (concept=us-gaap:CashAndCashEquivalentsAtCarryingValue, unit=USD, period_end=2025-09-30, accession=0001477333-25-000141)
- Operating income for the quarter was a loss of $157.97 million, showcasing the operational challenges faced by the company. (concept=us-gaap:OperatingIncomeLoss, unit=USD, period_end=2025-09-30, accession=0001477333-25-000141)
- Revenue data is Not specified in provided data. (concept=us-gaap:Revenues, unit=USD, period_end=2025-09-30, accession=0001477333-25-000141)
**Key Numbers:**
- Revenue: Not specified
- EPS: -0.26 (concept=us-gaap:EarningsPerShareDiluted, unit=USD/shares, period_end=2025-09-30, accession=0001477333-25-000141)
- Beat/Miss vs Expectations: Not specified in provided data
- Net Income: -90190000 (concept=us-gaap:NetIncomeLoss, unit=USD, period_end=2025-09-30, accession=0001477333-25-000141)
- Gross Margin: Not specified in provided data.
One gap that I need to fill in is the numerical anchor. If the bullet point contains a numerical value, it would be great if it also indicates a value field with the number and the unit, followed by the source reference, so that my script can easily create a JSON structure from them.
Thus, one thing that I did was to change the prompt result to provide a value field:
3) After each bullet, include a “Values:” block listing ALL numeric values mentioned in the bullet, in the order they appear.
Format for each value:
1) value=<canonical_numeric_value>, unit=<unit>
2) value=<canonical_numeric_value>, unit=<unit>
- Use full canonical numbers (no million/billion abbreviations).
- Preserve sign (negative if loss).
- If the bullet contains no numeric value, write: Values: None
- If a value is derived from scale words (million/billion), convert to full canonical number.
- If multiple value exist, Source References should be in ordered list as well as values (1:1 with Values)
Example output:
- Cash and cash equivalents stood at $1.05 billion, providing liquidity stability.
Values:
1) value=1052644000, unit=USD
Source Reference:
(concept=us-gaap:CashAndCashEquivalentsAtCarryingValue, unit=USD, period_end=2025-09-30, accession=0001477333-25-000141)
Now, the result will include a machine-readable intermediate format that is ready to be parsed into a structured format.
Create the Function To Evaluate Against the Source Table
Once the result contains a value in intermediate format, we need to create a function to evaluate the internal consistency and also the source consistency.
The first function evaluates the internal consistency. Since the output added an additional value field to make it easier to parse the value, it requires consistent matching with what is provided on the human-readable bullet point. This helps ensure that the bullet point is not lying in relation to its own declared anchors.
The second function is the function that we wanted to evaluate - it will be to parse the values and the source reference in the parentheses into a structured format and compare them with the source reference coming from the canonical table. This is to ensure the claim matches the source of truth.
I vibe-coded the evaluation function. It ended up with two checks wrapped in one evaluateSummary() function (in pseudocode):
function evaluateSummary(summaryText, canonicalRows):
claims, formatErrors = parseSummaryToClaims(summaryText)
internalResults = []
for claim in claims:
internalResults.push(validateTextMatchesValues(claim))
index = buildCanonicalIndex(canonicalRows)
sourceResults = []
for claim in claims:
sourceResults.push(validateValuesMatchCanonical(claim, index))
overallPass =
formatErrors is empty AND
all(internalResults.pass) AND
all(sourceResults.pass)
return {
overallPass,
formatErrors,
internalResults,
sourceResults
}
Create a Report Table
Then the report table should be short, easy to understand, and actionable. Thus, the value should be binary (PASS or FAIL) rather than numeric (1 to 5).
Why? Because binary values are easier to understand. When something is failing, developers know right away what the problem is.
Thus, the report value will contain:
Format Errors
internal failures: number (indicating how many failures there are)
source consistency: number (indicating how many failures there are)
overall: true/false
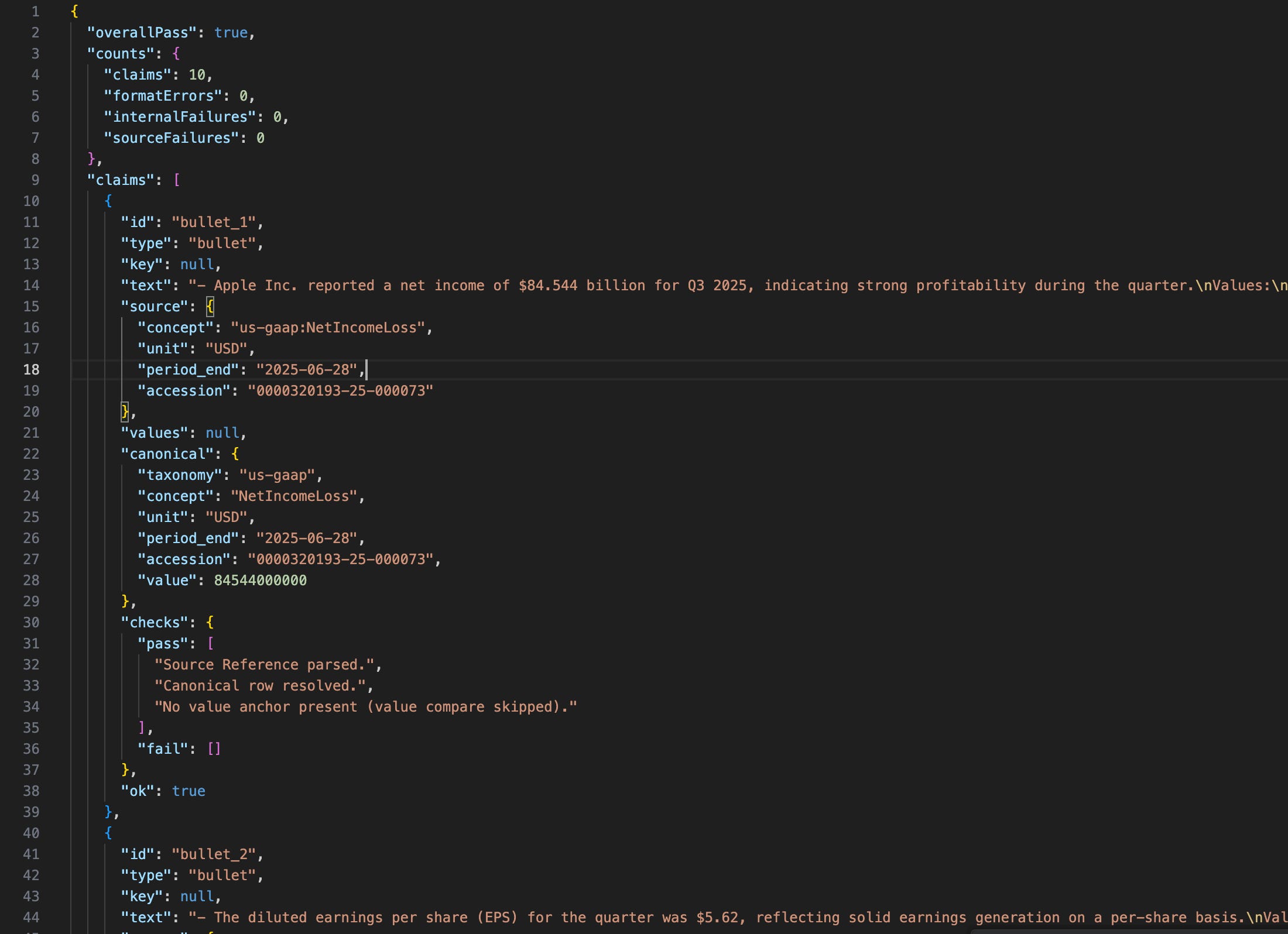
The output is a tiny report.json:
{
“overallPass”: true,
“counts”: {
“claims”: 10,
“formatErrors”: 0,
“internalFailures”: 0,
“sourceFailures”: 0
}
}
This makes it clear and actionable if an internal or source failure occurs.
I can then run this as a unit test in my CI pipeline each time to ensure the model produces an accurate numerical summary.
Takeaway
One of the biggest aha moments was understanding the type of failure mode. Once I realized the problem was deterministic, evaluating numerical accuracy felt less time-consuming and more like a unit test again.
Not every problem needs an LLM. You should push LLMs to the edge of the system, and keep everything as deterministic as possible.
Otherwise else you may be over-engineering or overcompensating in your application for something that can be solved more cheaply.
When you’re building with LLMs, how do you decide whether a failure is deterministic or subjective?